周末AI课堂 核技巧理论篇: 机器学习你会遇到的“坑”
AI课堂开讲,就差你了!
很多人说,看了再多的文章,可是没有人手把手地教授,还是很难真正地入门AI。为了将AI知识体系以最简单的方式呈现给你,从这个星期开始,芯君邀请AI专业人士开设“周末学习课堂”——每周就AI学习中的一个重点问题进行深度分析,课程会分为理论篇和代码篇,理论与实操,一个都不能少!
来,退出让你废寝忘食的游戏页面,取消只有胡吃海塞的周末聚会吧。未来你与同龄人的差异,也许就从每周末的这堂AI课开启了!
读芯术读者交流群,请加小编微信号:zhizhizhuji。等你。
全文共2571字,预计学习时长6分钟

暑期将至,不知道大家都计划好怎么度假了吗?先提醒一下,周末的课程不要忘记哦!
我们在前两周的《线性降维》和《非线性降维》中提到,降维的动机之一就是在高维空间上,如果我们感兴趣的只是某个低维分布,甚至样本只分布在某个低维流形上,数据的采样会面临困难。实际上,按照传统的办法,在高维空间计算数据的内积也会变得非常困难,所以我们尽量用降维的手段将一些操作拉到低维空间。
如果我们只考虑降维的话,似乎绕开了高维空间内积的麻烦,但对于某些实际问题,我们做的不再是降低维度,而是升高维度。
比如,对于一个二分类问题,我们的目标是寻找一个边界将两类样本很好的区分开,这个边界就叫做决策边界(decision boundary)。我们更希望得到一个线性的形式,线性的决策边界在数学上形式简单,同时具有可加性,非常容易做推广,而非线性不仅形式复杂,还很容易导致过拟合。
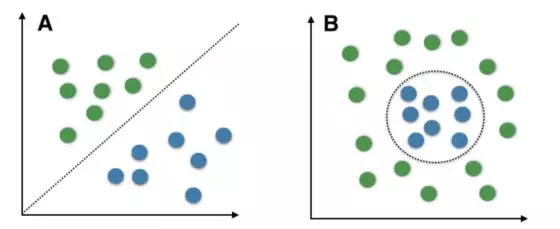
在二维的特征空间上,左边的图是线性边界,代表着样本线性可分,右边的图是非线性边界。
但在低维空间上,样本往往是线性不可分的,而我们又想要找到一个线性边界。那么我们就可以在输入变量的特征空间做一个转换:
![]()
,使得线性不可分的样本变得线性可分,同时也使得原本表现很差的线性决策边界在高维空间成为一个表现良好的决策边界:
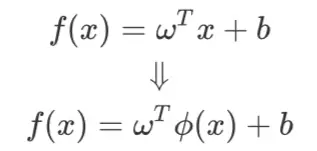
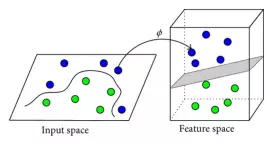
图为原始二维空间经过变换为三维空间,原本的非线性边界也变成了一个平面,这个平面就是高维空间的决策边界。
随之带来的问题则是,我们在估计参数的时候,无论是用Logistic Regression还是SVM,都会面临样本内积的计算,在低维空间我们需要算
![]()
,在高维空间我们需要算
![]()
。随着维度的升高,这样的内积计算就不再容易,我们甚至需要先做一个高维变换,再做内积,这样的计算复杂度就会非常高。

核技巧是什么
核技巧(kernel trick)是一种方法,我们用它可以非常方便地计算
![]()
。
很多教材上把SVM和核技巧放在一起,容易让人以为核技巧只能在SVM中使用,同时SVM的对偶问题和几何意义以及相应的最大硬间隔和最小软间隔与核技巧一起出现,给人一种核技巧非常难以理解的感觉。
其实呢,核技巧不只应用于SVM,大多数情况下,只要我们做了高维变换,同时需要计算
![]()
,那么我们都可以应用核技巧来简化运算。另一方面,核技巧其实非常简单,它就是用低维空间的内积来求高维空间的内积,省去了先做变换再求内积的痛苦。
以多项式核为例,我们定义某个样本x有个d分量:
![]()
我们做的高维变换是做一个多项式变换(degree=2),将d维扩展:
![]()
需要注意的是,上面的式子存在很多重复项,比如
![]()
和
![]()
,但这并不重要,我们会在后面它们都会写成统一的形式。我们对变换后的样本做内积:

我们分别叠加一次项,二次项,四次项,其中,四次项也可以拆成:
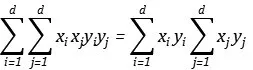
我们注意到,各元素的相应乘积再求和,正是内积的定义:
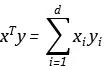
所以这个degree为2的多项式变换的内积可以写成:
![]()
这样,我们就可以不先进行高维变换,再在高维空间做内积,而是直接在在低维空间做内积,经过简单的加法就可以得到我们想要的结果。
我们把等号后边的形式叫做核函数(kernel function):
![]()
。同时,我们可以发现,核函数交换x,y应该保持不变,所以有
![]()
,这就是核函数的对称性。
另外,对于每一组样本都有着相应的核函数表示,我们就可以很方便的写成矩阵的形式:

这其实就是由
![]()
所构成的内积矩阵,而内积矩阵是半正定的。我们也把这个矩阵叫做核矩阵(kernel matrix).一般的,如果一个二元函数满足了对称性,以及构成的内积矩阵满足了半正定性,就可以被当作核函数来使用。这两个条件一起构成了传说中的Mercer Condition.
核技巧的使用
大家一定觉得,如果我们遇到以下两个条件,那么就可以用到我们的核技巧:
• 存在低维到高维的映射:
![]()
• 求解形式中只有映射的内积项,没有关于映射的奇数次项:
![]()
其实呢,有一个更为强大的定理叫做表示定理(Representer Theorem)告诉我们,只要优化问题中的正则化项是递增的,优化函数的解总可以表示成核函数的线性组合,换而言之,满足表示定理的内蕴属性的优化函数就一定可以用kernel trick 来进行非线性拓展。
SVM中的核技巧
这可能是最著名的核技巧的使用场景。在SVM中,我们如果考虑最大硬间隔,优化问题会变成异类支持向量到决策边界的距离之和最大化,同时满足样本划分正确:
![]()
将数据从低维映射到高维:
![]()
继续可以得到参数化的对偶问题(这个足够经典,就不展开讲了):
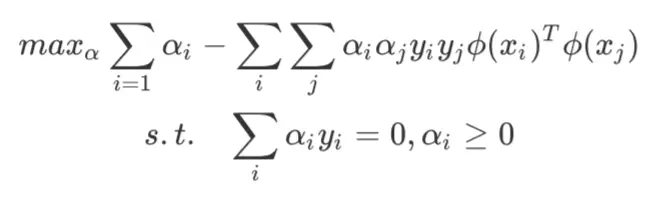
那么我们在计算
![]()
时就可以采用核技巧。如果你也是这样理解SVM中的核技巧,那么这里面其实还隐藏另外一种更深刻的理解方法,有兴趣的同学可以想一想:在对约束添加拉格朗日乘子后,对参数求导的过程,其实就是将参数表示为
![]()
的线性组合,而后续我们要做参数与
![]()
岭回归(ridge regression)中的核技巧
岭回归就是添加了
![]()
正则化的最小二乘估计,优化函数为:

将数据从低维映射到高维:

因为正则化项
![]()
明显满足单调递增,所以根据表示定理,优化函数的解可以表示为核函数的线性组合,即:

所以我们把优化函数解的核函数形式代入到优化函数中,可得:
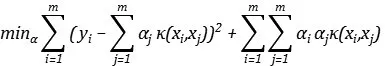
所以,我们就可以把传统的岭回归拓展为非线性学习方法。
值得注意的是,使用kernel trick时,往往会有过拟合的风险,因为维数变高,意味着在原始空间中的决策边界会变的非常复杂。但SVM最大间隔划分样本下,却在一定程度上减弱了这样的过拟合风险。这也是为什么我们要在SVM中频繁使用kernel trick,而在其他地方却很少使用的原因之一。

读芯君开扒
课堂TIPS
• 正是因为表示定理太过强大,才使得我们将kernel trick用到各类学习器上成为可能。事实上,我们可以同样可以在Logistic Regression上使用kernel trick,推导方式与岭回归类似。
• 不同的核函数会将原始的低维空间映射到不同维数的高维空间,例如,多项式核函数对应的仍然是有限维,但是高斯核函数会对应着的却是无限维,因为在推导过程中我们会发现高斯核函数的指数项对应着一个无限维的泰勒展开。
• 文中提到的Mercer Condition只是核函数的充分条件,而非必要条件。
• 大部分的书中都会写着多项式核函数:
![]()
,而有的书中还会添加两个参数:
![]()
,而这两个参数只是对数据进行了放缩。比如,在d=2时,其实就是在做多项式变换时,常数项变为
![]()
,一次项乘以
![]()
,二次项乘以
![]()
。
• 在上一节中,我们提到了kernel PCA,它就是先把样本映射到高维空间,然后在高维空间中做PCA,在具体的操作中,就是把原本的协方差矩阵的特征值分解换为核矩阵的特征值分解。
留言 点赞 发个朋友圈
我们一起探讨AI落地的最后一公里



文章评论
共有 51 位网对文章表示很赞! 查看完整内容